文章主要是使用元学习的方法来做少量数据下的自适应tts。
训练:
- 输入是hts的文本特征和f0,经过上采样层作为wavenet的local condition。
- 使用多说话人的数据集来自适应说话人,因此会学习到一个说话人的embedding,这个embedding作为wavenet的global condition
三种自适应的策略:
- 在保持wavenet权重不变的情况下学习speaker embedding
- 用SGD fine-tuning整个模型
- 用训练好的speaker encoder来预测speaker embedding
基本框架如下: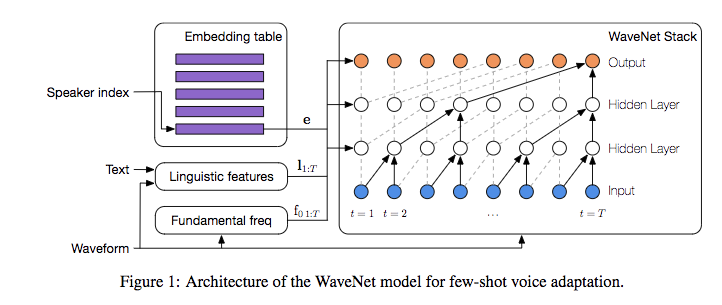
给定speaker的身份为$s$,那么模型可以表达为:
训练过程中的文本特征和f0是从成对的文本和音频从提取出来的,测试的时候都是用模型(参考heiga 2016年的文章)预测出来的。
自适应方法
非参数化的自适应
首先训练一个multi speaker的wavenet模型,框架如上,这样会得到两种参数:
- speaker embedding $e$
- 共享的wavenet参数 $w$
- 单独对speaker emebdding进行自适应
针对一个新说话人的少量数据,随机初始化一个$e_{demo}$, 固定$w$, 输入该说话人的少量数据的文本特征和f0,来学习该说话人的embedding
- 对整个模型进行自适应
相比上面,同时把$w$也加到自适应的参数里面
这两种方法都可以实现少量数据的自适应,但是训练过程不太一样,在第一种方法中,由于speaker embedding只是低维向量,不是那么容易过拟合,但是在第二种方法中,参数很多,自适应的时候容易对少量数据过拟合,因此需要留出10%的数据计算对数似然作为指标使得模型的训练在适当的时候
能够停止,同时还需要采用1中训练好的embedding作为2中的初始化,同时模型的初始化能够极大的提升泛化能力。
参数化的自适应
这里主要是用辅助的speaker encoder从给定的数据中预测speaker embedding,同时这个encoder和wavenet是从头一起训练的。
去除说话人相关的信息
给定的输出是文本特征和f0,但是f0是高度的说话人相关的信息,因此为了尽量让输入的特征说话人无关,因此对f0进行了normalize。
指标
- 自然度
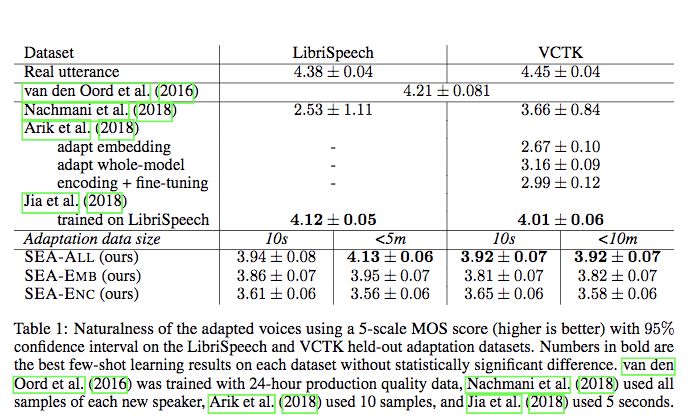
- 相似度
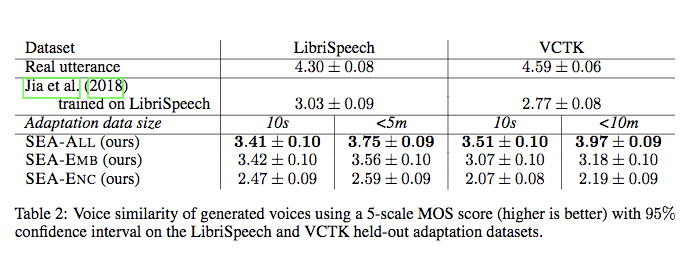 另外论文中还给出了说话人识别的指标,就不贴出来了。
另外论文中还给出了说话人识别的指标,就不贴出来了。