简介
文章是基于18年2月份的WaveRNN来改进, 不同的是LPCNET是用来作为vocoder的,同时在相同的网络结构下能够得到更好的音质,每秒能进行30亿次的浮点数运算,能够支持在比较差的设备,手机等等上运行。实际上也是进行指令级的优化。
文章给了代码,从代码中其实能够学到很多:)。
基本框架
基本模型如下图: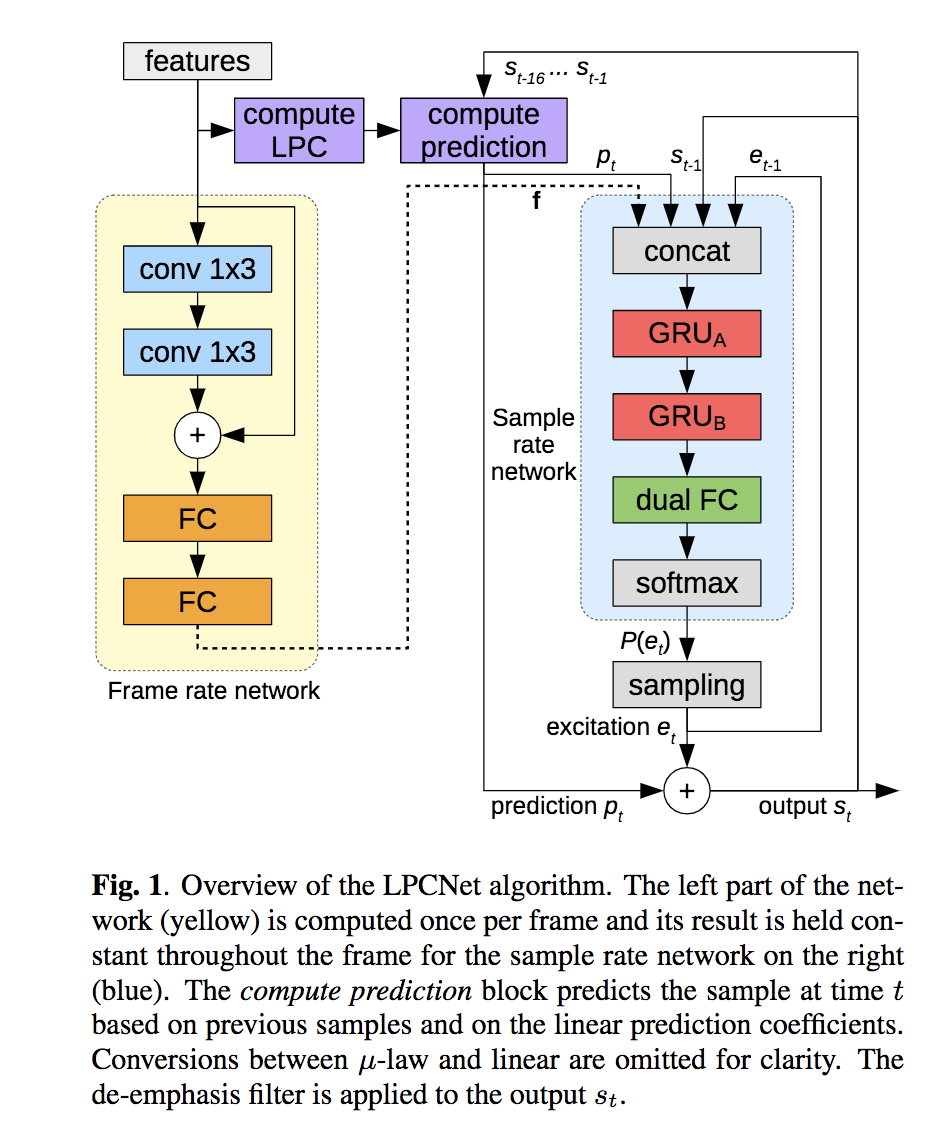
特征参数
输入的音频为16k,提取的特征为20维,每一帧是10ms(160个采样点),特征包括18维的bark-scale cepstral coefficient和2维的音调参数(period, correlation)。
网络训练的时候,每一个batch里面有20帧,由于帧级网络有3x1的卷积,因此接受域是5。
预加重和量化
之前的wavenet是使用8 bit的u-law来量化信号点,使得最后输出为256的分类任务,这是由于音频的能量大都集中在基频,但是在高频仍然会有一些白噪声,尤其是16k的音频对高频有一定的倾斜。
为了避免这个问题,WaveRNN采用的高、低8位的方法使得最后的分布是16bit的。在这篇文章中,采用了一阶预加重滤波器过训练数据,滤波器如下:
合成结果可以通过逆滤波器得到最后的输出
这种方法能够有效的减少噪声,并且使得8bit可以作为高音质音频的输出。
线性估测
线性预测的值可以从之前的采样点计算
$s_{t}$是采样点在t时刻的值,$a_k$是M阶线性预测系数的值,并且是可以根据18维的bark-scale cepstrum 计算出来的。
因此可以使用线性预测器来帮助神经网络进行训练,这里可以直接预测激励参数$e{t}=s{t}-p{t}$,而不是采样点的值$s{t}$,能够帮助减少u-law的噪音,因为激励参数的幅度相比原始信号点更低。
但是在输入并没有直接给$e{t-1}$,而是$e{t-1}, s_{t-1}, p_t$这样会更好的帮助训练。
输出层
输出层上才用了双层的线性层来更容易的计算输出概率。
$W_1$和$W_2$是线性层的权重,$a_1$和$a_2$是权重系数。论文中提到该方法有轻微的提升音频质量。
稀疏矩阵
为了使得计算复杂度降低,对网络自回归部分比较大的权重$GRU_A$进行了稀疏化。如果对权重中元素逐个稀疏,会有效的阻止矢量化,因此才用了分块(block-sparse)的稀疏方法。
训练的时候从dense matrix开始,过程中将值比较低的块强制置为0,知道达到期望的稀疏度,实验发现16x1的块比较有效。
除了非零的块,还保留了稀疏矩阵对角线的值,因为这些值最有可能非零,同时对角线元素很容易进行矢量乘积。
Embedding和线性计算简化
论文中对u-law之后的值并没有进行one-shot表示,而是过一个embedding层期望做到一个线性变化。
由于这个embedding得输出是直接给到gru层,因此可以对矩阵的计算做一定的简化,提前合并计算,减少计算复杂度。
主要就是将embedding的weight和non-recurrent的weight先做乘积得到新的embedding lookup table。
采样过程
从概率中直接采样可能会给最后的输出带来噪音。
在18年icassp的FFTNet文章中,由于它的condition带有f0,因此会给非静音的概率值乘以一个常数$c=2$,有点类似基于temperature的采样。
在该文章中,同样有picth参数,因此没有做一个二分类的决策,而是才用下面的公式计算当前概率应该如何变化:
$g_p$是pitch系数,在采样时,选取一个常数,保证任何在该常数以下的概率值都为0,最后重新分配概率,得到最后的概率分布。
$R(\cdot)$表示重新分配概率,最后选取的T为0.002
训练加噪
整个训练的输入如下:
因为在训练的时候,我们给的都是真实输入,但是在合成的时候是自回归式的合成,因此会造成训练和测试的不匹配,在训练的输入中加入噪音能够增强网络的鲁棒性。
由于有线性预测作为特征,因此加入的噪音的细节格外重要。
如果在训练的信号中加入噪音,预测干净的激励,这会使得合成的声音比较像分析合成的声码器。
但是像上图中加入噪音,能显著减少信号点上的误差,因为输入的线性预测同样用于输出的采样点的计算。
噪音是在ulaw之后加上的,分布为uniform [-3, 3],实际加入噪音的方式可以参考代码,稍有变动。
实验结果
复杂度
整个网络除了前面并行的部分,大部分的计算都来自两个GRU和最后的线性层。
因为模型相比WaveRNN要小,所以浮点数运算肯定会比较快,论文中为2.8GFLOPS和10GFLOPS,其他的诸如WaveNet,FFTNet,SampleRNN肯定会慢更多。
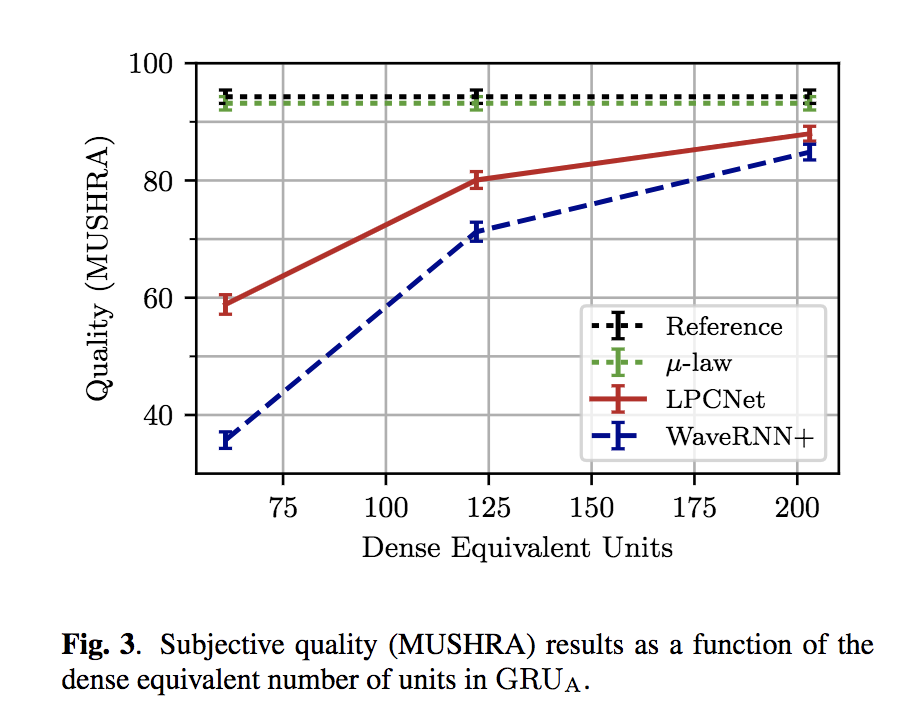
主观指标
下图是和wavernn相比的指标: